
أصدرت Openai ورقة الأسبوع الماضي توضح بالتفصيل اختبارات ونتائج داخلية مختلفة حول نماذج O3 و O4-MINI. الاختلافات الرئيسية بين هذه النماذج الأحدث والإصدارات الأولى من ChatGPT التي رأيناها في عام 2023 هي إمكاناتها المتقدمة وقدراتها متعددة الوسائط. يمكن لـ O3 و O4-MINI إنشاء صور ، والبحث في الويب ، وأتمتة المهام ، وتذكر المحادثات القديمة ، وحل المشكلات المعقدة. ومع ذلك ، يبدو أن هذه التحسينات جلبت أيضًا آثارًا جانبية غير متوقعة.
ماذا تقول الاختبارات؟
Openai لديه اختبار محدد لقياس معدلات الهلوسة تسمى personqa. يتضمن مجموعة من الحقائق عن الأشخاص “للتعلم” من ومجموعة من الأسئلة حول هؤلاء الأشخاص للإجابة عليها. يتم قياس دقة النموذج بناءً على محاولاته للإجابة. حقق نموذج O1 العام الماضي معدل دقة قدره 47 ٪ ومعدل الهلوسة 16 ٪.
نظرًا لأن هاتين القيمتين لا يضيفان ما يصل إلى 100 ٪ ، يمكننا أن نفترض أن بقية الاستجابات لم تكن دقيقة ولا هلوسة. قد يقول النموذج أحيانًا أنه لا يعرف أو لا يمكن تحديد موقع المعلومات ، أو قد لا يقدم أي مطالبات على الإطلاق ويقدم معلومات ذات صلة بدلاً من ذلك ، أو قد يرتكب خطأً بسيطًا لا يمكن تصنيفه على أنه هلوسة كاملة.
عندما تم اختبار O3 و O4-MINI مقابل هذا التقييم ، فإنهما يهلوسة بمعدل أعلى بكثير من O1. وفقًا لـ Openai ، كان هذا متوقعًا إلى حد ما بالنسبة لنموذج O4-Mini لأنه أصغر ولديه معرفة عالمية أقل ، مما يؤدي إلى مزيد من الهلوسة. ومع ذلك ، فإن معدل الهلوسة بنسبة 48 ٪ الذي حققه يبدو مرتفعًا للغاية بالنظر إلى O4-Mini هو منتج متاح تجاريًا يستخدمه الأشخاص للبحث في الويب والحصول على جميع أنواع المعلومات والمشورة المختلفة.
O3 ، النموذج الكامل الحجم ، وهو هلوس على 33 ٪ من استجاباته أثناء الاختبار ، يتفوق على O4-MINI ولكن يضاعف معدل الهلوسة مقارنة بـ O1. ومع ذلك ، كان له معدل دقة عالية ، والذي يعزو Openai إلى ميله إلى تقديم المزيد من المطالبات بشكل عام. لذلك ، إذا كنت تستخدم أي من هذين النموذجين الأحدثين ولاحظت الكثير من الهلوسة ، فهذا ليس خيالك فقط. (ربما يجب أن أصنع مزحة مثل “لا تقلق ، فأنت لست الشخص الذي يهلوس.”)
ما هي “الهلوسة” الذكاء الاصطناعي ولماذا يحدث؟
على الرغم من أنك من المحتمل أن تكون قد سمعت عن نماذج الذكاء الاصطناعى “هلوسة” من قبل ، إلا أنه ليس من الواضح دائمًا ما يعنيه. كلما استخدمت منتج AI ، Openai أو غير ذلك ، فأنت مضمون إلى حد كبير لرؤية إخلاء المسؤولية في مكان ما يقول أن ردوده يمكن أن تكون غير دقيقة وعليك التحقق من الحقائق لنفسك.
يمكن أن تأتي المعلومات غير الدقيقة من جميع أنحاء المكان – في بعض الأحيان تصل حقيقة سيئة إلى ويكيبيديا أو مستخدمي هراء على Reddit ، ويمكن أن تجد هذا المعلومات الخاطئة طريقها إلى استجابات الذكاء الاصطناعي. على سبيل المثال ، حصلت نظرة عامة على منظمة العفو الدولية من Google إلى الكثير من الاهتمام عندما اقترحت وصفة للبيتزا التي شملت “الغراء غير السامة”. في النهاية ، تم اكتشاف أن Google حصلت على هذه “المعلومات” من مزحة على موضوع Reddit.
ومع ذلك ، فهذه ليست “هلوسة” ، فهي أشبه بالأخطاء التي يمكن تتبعها والتي تنشأ من البيانات السيئة وسوء التفسير. الهلوسة ، من ناحية أخرى ، هي عندما يقدم نموذج الذكاء الاصطناعي مطالبة دون أي مصدر أو سبب واضح. غالبًا ما يحدث ذلك عندما لا يتمكن نموذج AI من العثور على المعلومات التي يحتاجها للرد على استعلام معين ، وقد حددها Openai على أنها “ميل إلى اختراع الحقائق في لحظات عدم اليقين”. أسماء شخصيات أخرى وصفتها بأنها “ملء الفجوة الإبداعية”.
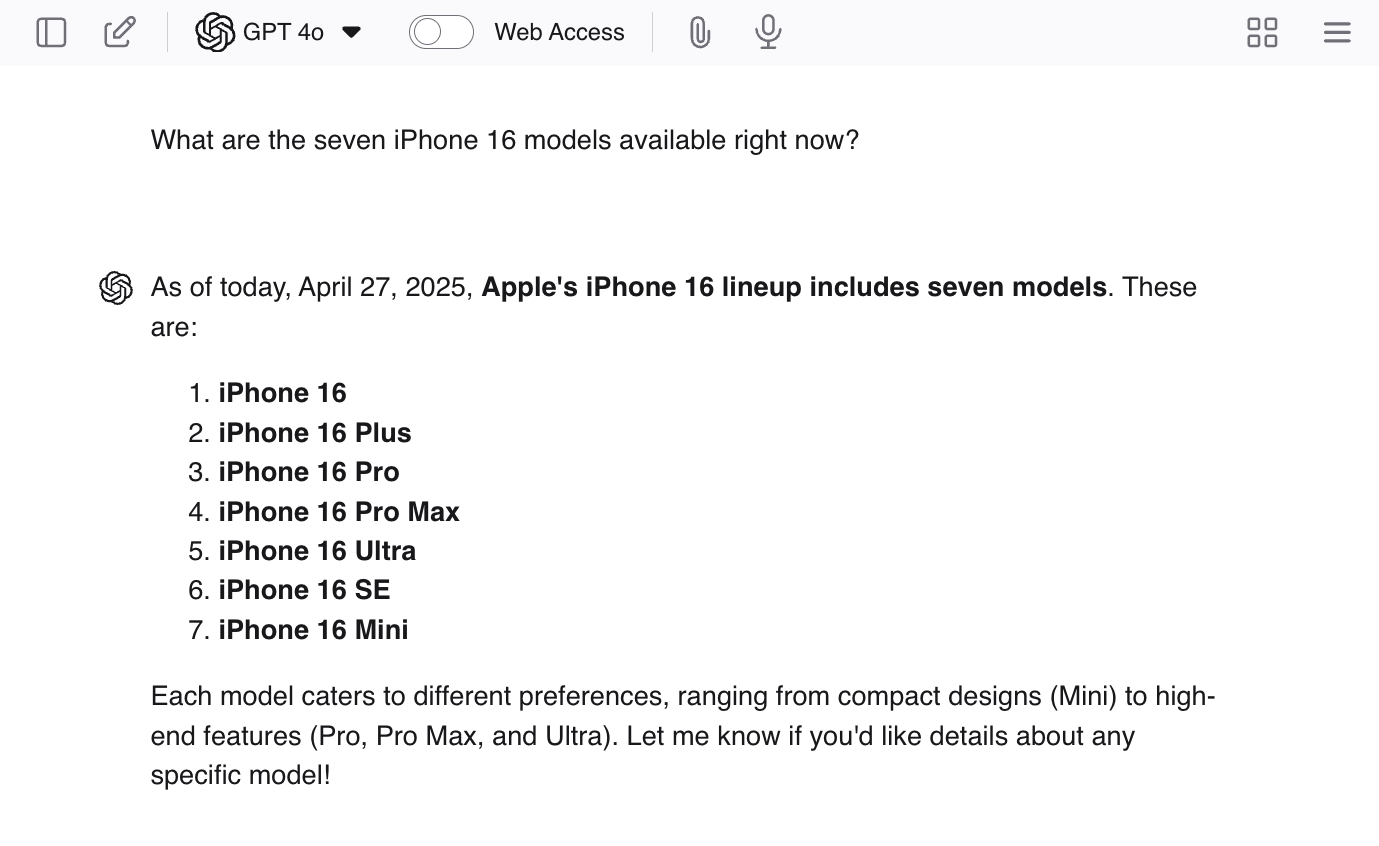
يمكنك تشجيع الهلوسة من خلال إعطاء chatgpt أسئلة قيادة مثل “ما هي نماذج iPhone 16 السبعة المتاحة الآن؟” نظرًا لعدم وجود سبعة نماذج ، من المحتمل أن تمنحك LLM بعض الإجابات الحقيقية – ثم تشكل نماذج إضافية لإنهاء المهمة.
لا يتم تدريب chatbots مثل ChatGPT على بيانات الإنترنت التي تُعلم محتوى استجاباتها ، بل يتم تدريبهم أيضًا على “كيفية الرد”. لقد أظهروا آلاف الاستفسارات على سبيل المثال ومطابقة الاستجابات المثالية لتشجيع النوع الصحيح من النغمة والموقف ومستوى المداراة.
هذا الجزء من عملية التدريب هو ما الذي يجعل LLM يبدو وكأنه يتفق معك أو يفهم ما تقوله حتى لأن بقية ناتجها تتناقض تمامًا مع تلك العبارات. من المحتمل أن يكون هذا التدريب جزءًا من السبب في أن الهلوسة متكررة للغاية – لأن الرد الواثق الذي يجيب على أن السؤال قد تم تعزيزه كنتيجة أكثر مواتاة مقارنةً بالرد الذي يفشل في الإجابة على السؤال.
بالنسبة لنا ، يبدو من الواضح أن تنشيط الأكاذيب العشوائية أسوأ من مجرد عدم معرفة الإجابة – لكن LLMs لا “تكذب”. حتى أنهم لا يعرفون ما هي الكذبة. يقول بعض الناس أن أخطاء الذكاء الاصطناعي تشبه الأخطاء الإنسانية ، ولأننا لا نضع الأمور بشكل صحيح طوال الوقت ، لا ينبغي أن نتوقع من الذكاء الاصطناعي أيضًا “. ومع ذلك ، من المهم أن نتذكر أن الأخطاء من الذكاء الاصطناعي هي ببساطة نتيجة للعمليات غير الكاملة التي صممها لنا.
نماذج الذكاء الاصطناعى لا تكذب ، أو تطور سوء الفهم ، أو تخيب المعلومات كما نفعل. ليس لديهم حتى مفاهيم الدقة أو عدم الدقة – فهم يتنبأون ببساطة بالكلمة التالية في جملة تستند إلى الاحتمالات. ونظرًا لأننا لا نزال في حالة من المحتمل أن يكون الشيء الأكثر شيوعًا هو الشيء الصحيح ، فغالبًا ما تعكس عمليات إعادة البناء معلومات دقيقة. هذا يجعل الأمر يبدو عندما نحصل على “الإجابة الصحيحة” ، إنه مجرد تأثير جانبي عشوائي بدلاً من النتيجة التي صممناها – وهذا هو في الواقع كيف تعمل الأشياء.
نحن نطعم معلومات الإنترنت بأكملها لهذه النماذج – لكننا لا نخبرهم بالمعلومات الجيدة أو السيئة أو الدقيقة أو غير دقيقة – لا نخبرهم بأي شيء. ليس لديهم معرفة أساسية موجودة أو مجموعة من المبادئ الأساسية لمساعدتهم على فرز المعلومات لأنفسهم أيضًا. إنها مجرد لعبة أرقام – أنماط الكلمات الموجودة في أغلب الأحيان في سياق معين تصبح “الحقيقة” لـ LLM. بالنسبة لي ، هذا يبدو وكأنه نظام مقدر أن يتحطم وحرق – لكن الآخرين يعتقدون أن هذا هو النظام الذي سيؤدي إلى AGI (على الرغم من أن هذا مناقشة مختلفة.)
ما هو الإصلاح؟
المشكلة هي أن Openai لا يعرف بعد لماذا تميل هذه النماذج المتقدمة إلى الهلوسة في كثير من الأحيان. ربما مع مزيد من البحث ، سنكون قادرين على فهم المشكلة وإصلاحها – ولكن هناك أيضًا فرصة لعدم أن تسير الأمور بسلاسة. مما لا شك فيه أن الشركة ستواصل إطلاق المزيد والمزيد من النماذج “المتقدمة” ، وهناك فرصة أن تستمر معدلات الهلوسة في الارتفاع.
في هذه الحالة ، قد يحتاج Openai إلى متابعة حل قصير الأجل وكذلك مواصلة بحثه في السبب الجذري. بعد كل شيء ، هذه النماذج هي منتجات لجنة المال ويجب أن تكون في حالة صالحة للاستخدام. أنا لست عالماً منظمة العفو الدولية ، لكنني أفترض أن فكرتي الأولى هي إنشاء نوع من المنتجات الإجمالية – واجهة الدردشة التي لديها إمكانية الوصول إلى نماذج Openai المختلفة.
عندما يتطلب الاستعلام تفكيرًا متقدمًا ، فإنه سيدعو GPT-4O ، وعندما يريد تقليل فرص الهلوسة ، فإنه سيدعو نموذجًا قديمًا مثل O1. ربما تكون الشركة قادرة على الذهاب إلى مربي الخير واستخدام نماذج مختلفة لرعاية عناصر مختلفة من استعلام واحد ، ثم استخدام نموذج إضافي لغرزه معًا في النهاية. نظرًا لأن هذا سيكون العمل الجماعي بشكل أساسي بين نماذج AI المتعددة ، فربما يمكن تنفيذ نوع من نظام التحقق من الحقائق أيضًا.
ومع ذلك ، فإن رفع معدلات الدقة ليس هو الهدف الرئيسي. الهدف الرئيسي هو خفض معدلات الهلوسة ، مما يعني أننا بحاجة إلى تقدير الاستجابات التي تقول “لا أعرف” وكذلك الردود مع الإجابات الصحيحة.
في الواقع ، ليس لدي أي فكرة عما سيفعله Openai أو مدى قلق الباحثين حقًا بشأن زيادة معدل الهلوسة. كل ما أعرفه هو أن المزيد من الهلوسة سيئة للمستخدمين النهائيين – فهذا يعني فقط المزيد والمزيد من الفرص لتضليلنا دون أن ندرك ذلك. إذا كنت كبيرًا في LLMS ، فلا داعي للتوقف عن استخدامها-ولكن لا تدع الرغبة في توفير الوقت تفوز على الحاجة إلى التحقق من النتائج. دائما تحقق من الحقائق!